Click to see package details
# Libraries
packages <-
c("tidyverse",
"sergeant",
"tictoc"
)
if (length(setdiff(packages,rownames(installed.packages()))) > 0) {
install.packages(setdiff(packages, rownames(installed.packages())))
}
invisible(lapply(packages, library, character.only = TRUE))
knitr::opts_chunk$set(
comment = NA,
fig.width = 12,
fig.height = 8,
out.width = '100%'
)Introduction
At Redwall, we have been in nonstop exploration of new data sets over the last couple of years. As our data grows and the targets of interest get bigger, we have been finding the old method of loading csv’s from disc, and working on the full set in memory is becoming less optimal. We thought we would try Apache Drill via the {sergeant} package created by Bob Rudis, a prolific R developer. Apache Drill seems amazing because it would allow us to be agnostic as to data source and type. Usually, we write blog posts to show off things we have learned which are actually working. The punchline in this case though, is that we were not able to get where we hoped so far with Drill. We will chronicle what we have done so far, and where we are still falling short.
Recall in Finding the Dimensions of secdatabase.com from 2010-2020 - Part 2, we were able to query a data set which was over 20GB with the AWS Athena query service with pretty much instant response. With Apache Drill on one node on our 2005 Apple iMac with 8GB of RAM, queries with a couple of joins and some aggregation were taking at least 30 minutes, but usually much longer on a much smaller data set (if they didn’t crash our computer altogether). This could well be our machine, something we did wrong in configuring, poor query management or all of the above. We are writing this post in hopes of a response from experts, as well as to help others who might be trying to understand how to use Java, Drill or even the command line from RStudio. We promise to update the post with any feedback, so that it provides a pathway to others seeking to do the same.
Yelp Academic Data Set
We were hoping to avoid downloading it, but then we found Bob Rudis’ excellent Analyzing the Yelp Academic Dataset w/Drill & sergeant blog post and became intrigued by the possibility of having the flexible connection it offered, agnostic about storage and data formats. The Yelp Academic data set is about 10GB in size and took us over an hour to download, and are summarized in the image from the web page above. We hoped that we might be able to use it to explore the death rate of businesses in areas with differing COVID-19 mask and other non pharmaceutical interventions. Unfortunately, this is not possible at the moment, because it only runs through the end of 2019. The files are all in JSON format, and were one of the original examples given on the Apache Drill website and with the {sergeant} package. Shown below, the “business” file is the smallest, and “reviews” are by far the largest. Users visit businesses and give reviews, check-ins or tips, so the two main identifiers which tie the tables together are business_id and the user_id. There is a lot of opportunity to practice joins and aggregations if you can get it to work.
Click to see code generating output
d <-
file.info(
list.files(
path = "/Volumes/davidlucey/aDL/data/yelp_dataset/",
pattern = ".json",
full.names = TRUE
)
)[c(1, 2)]
data.frame(file = stringr::str_extract(rownames(d), "yelp.*"), size = d$size) file size
1 yelp_dataset//yelp_academic_dataset_business.json 152898689
2 yelp_dataset//yelp_academic_dataset_checkin.json 449663480
3 yelp_dataset//yelp_academic_dataset_review.json 6325565224
4 yelp_dataset//yelp_academic_dataset_tip.json 263489322
5 yelp_dataset//yelp_academic_dataset_user.json 3268069927 file size
1 yelp_dataset//yelp_academic_dataset_business.json 152898689
2 yelp_dataset//yelp_academic_dataset_checkin.json 449663480
3 yelp_dataset//yelp_academic_dataset_review.json 6325565224
4 yelp_dataset//yelp_academic_dataset_tip.json 263489322
5 yelp_dataset//yelp_academic_dataset_user.json 3268069927Background on Drill
To quote from this guide: Apache Drill - Quick Guide.
Apache Drill is a low latency schema-free query engine for big data. Drill uses a JSON document model internally which allows it to query data of any structure. Drill works with a variety of non-relational data stores, including Hadoop, NoSQL databases (MongoDB, HBase) and cloud storage like Amazon S3, Azure Blob Storage, etc. Users can query the data using a standard SQL and BI Tools, which doesn’t require to create and manage schemas.
We also found the excellent chart shown in SQL on Everything with Apache Drill below on What is Apache Drill and how to setup your Proof-of-Concept
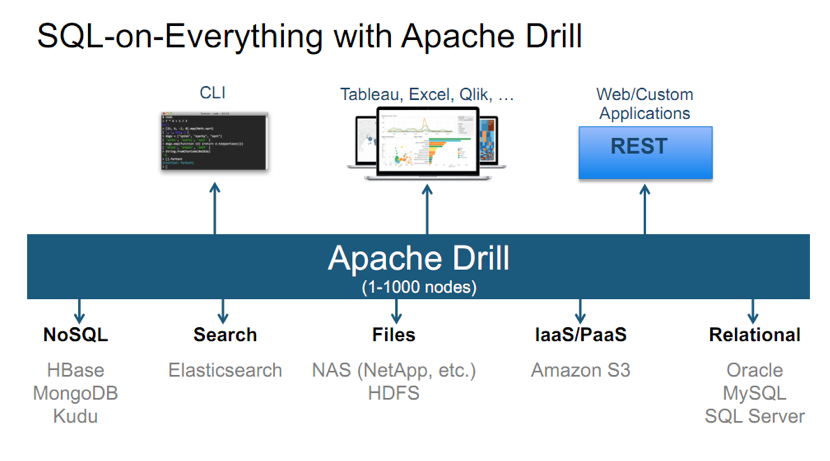
SQL on Everything with Apache Drill
If this could work, it feels like we could fire it up and use it in just about any of our data sources or types. In this post, we are just going to use with a single node as we are only working with one small computer, but it looks like it should be easy to add additional nodes to speed things up.
Sergeant
As usual, none of this would have been possible without an amazing open source package created and shared by a real developer, often in their free time. In this case, we relied on Bob Rudis’ (Drill) {sergeant} package, blog posts and bookdown manual Drill in More than 10 Minutes. He explains that he set up the interface because he saw Drill as a streamlined alternative to SPARK for those not needing the ML components (ie: just needing to query large data sources of disparate types like json, csv, parquet and rdbms). The package allows to connect to Drill via dplyr interface with the src_drill() function, and also the REST API with drill_connection(). Before using {sergeant} though, Java, Drill and Zookeeper must be installed.
Java
Drill requires Oracle JDK 1.8, which is several generations earlier than the version we currently have installed on our Mac. In our first year or two, we tangled with Java because we really wanted to use {tabulizer} to extract tables from pdfs. We burned a lot of time trying to understand the versions and how to install and point to them on Stack Overflow. Just last week, we saw a post looking for advice on loading the {xlsx} package, which depends on Java, as well. One of the magical discoveries we made was Java Environment. Go to Java SE Development Kit 8 Downloads, choose the latest Mac Version of 1.8, and install the .dmg. Then on a Mac, brew install jenv, and it is off to the races. Here we show the Java versions on our machine from the Terminal.
jenv versions system
1.6
1.6.0.65
1.8
1.8.0.261
14
14.0
* 14.0.2 (set by /Users/davidlucey/.jenv/version)
oracle64-1.6.0.65
oracle64-1.8.0.261
oracle64-14.0.2In our first pass, we didn’t understand the different paths, but it doesn’t matter anymore. Just copy/paste the name and put in in the following command and the problem is solved.
jenv global 1.8And we are good to go, plus we can easily switch back when we are done. It is hard to understate how grateful we are to people who built jenv and brew.
jenv version1.8 (set by /Users/davidlucey/.jenv/version)Setting up Apache Drill
The latest version (December 2019) can be downloaded from here, but note with the sale of MapR to Hewlett Packard last year, the project is reported to have been “orphaned”. We took the download and install route, though we subsequently found that using brew install apache-drill might have avoided some of the questions we now have about symlinking (see Zookeeper section below). Apache Drill : Quick Setup and Examples gives step-by-step instructions which might have helped if we had it while installing, but currently have Drill installed in /usr/local/apache-drill-1.1.7.0/ (shown below) though the {sergeant} manual directs to install in the drill/ folder.
ls /usr/local/apache-drill-1.17.0/binauto-setup.sh
drill-am.sh
drill-conf
drill-config.sh
drill-embedded
drill-embedded.bat
drill-localhost
drill-on-yarn.sh
drillbit.sh
hadoop-excludes.txt
runbit
sqlline
sqlline.bat
submit_plan
yarn-drillbit.shHere there are a few options for running Drill. Running bin/drill-embedded from this this folder, a SQL engine comes up, and queries can be run straight from the command line from a basic UI. We wanted to query from RStudio, so we had another step or two. First, we had to configure the drill-override.conf file in the /conf/ folder above. We followed Bob Rudis’ instructions and named our cluster_id “drillbit1” and zk.connect to our local path as shown below. After these steps, we are able to run and show some sample queries using Drill.
grep "^[^#;]" /usr/local/apache-drill-1.17.0/conf/drill-override.confdrill.exec: {
cluster-id: "drillbits1",
zk.connect: "localhost:2181",
store.json.reader.skip_invalid_records: true,
sys.store.provider.local.path: "/usr/local/apache-drill-1.17.0/conf/storage.conf"
}Once this was all in place, the start up to run Drill in the local environment is pretty easy just running bin/drillbit.sh start from in the Terminal. We are not actually running it here in RMarkdown because it froze up the chunk while Drill was running.
# Run in Terminal not in .rmd chunk
~/usr/local/apache-drill-1.17.0/bin/drillbit.sh startWe actually ran it separately in the background from Terminal. Below, we are able to check the status and see that drillbit is running.
/usr/local/apache-drill-1.17.0/bin/drillbit.sh status/usr/local/apache-drill-1.17.0/bin/drill-config.sh: line 144: let: lineCount=: syntax error: operand expected (error token is "=")
/usr/local/apache-drill-1.17.0/bin/drill-config.sh: line 144: let: lineCount=: syntax error: operand expected (error token is "=")
/usr/local/apache-drill-1.17.0/bin/drill-config.sh: line 144: let: lineCount=: syntax error: operand expected (error token is "=")
/usr/local/apache-drill-1.17.0/bin/drill-config.sh: line 144: let: lineCount=: syntax error: operand expected (error token is "=")
drillbit is running.The {sergeant} manual also talked about allocating more memory, but we didn’t know how to do this or if it was possible on our small system. There were also other options for setting up a Drill connection, like Docker, so maybe that would help us resolve our issues. It could be that these factors are why we haven’t gotten it to work as well as we hoped.
Zookeeper
There is also the option to run Drill in parallel using Zookeeper discussed in the {sergeant} manual. In the Wiring Up Zookeeper section, it says to have drill in usr/local/drill/ for Mac, and to symlink to the full versioned drill to make it easier to upgrade, but it was vague about this. We noticed that we have a separate folder (~/drill/) in our home directory which has a file udf/ file from the installation, which we understand pertains to “user defined functions” (a subject touched on in Recipe 11 of the {sergeant} manual). We weren’t sure exactly which folder was referred to and reading on Stack Overflow, but we were about three steps away from understanding how this all fit together, so our configuration may not be optimal. When we used Zookeeper with the ODBC connection in parallel instead of “Direct to”Drillbit", if anything, we got slower query times as we will discuss below.
Configuring the Drill Path Storage Plug-in
Drill is connected to data sources via storage plug-ins. The {sergeant} manual mentioned the Drill Web UI passing, but we didn’t realize at first that pulling up localhost:8047 in our browser was an important component for profiling queries. We will show a few of the pages below.
# Run in terminal not .rmd chunk
/usr/local/apache-drill-1.17.0/bin/drill-localhostIn his Yelp blog post, Bob Rudis used “root.dfs” as the path to the Yelp tables. At first, we didn’t understand what this referred to, but it is used as the path to the root of the file system where the data is stored as configured in the storage plug-ins. The “Storage” page of the Drill Web App is in Drill Web App Plug-Ins below. Both his and the Apache documentation also refer the “cp” path to refer to example JAR data in the Drill “classpath”. In addition to the two defaults, all the plug-ins available for hive, mongo, s3, kafka, etc. are also shown below.
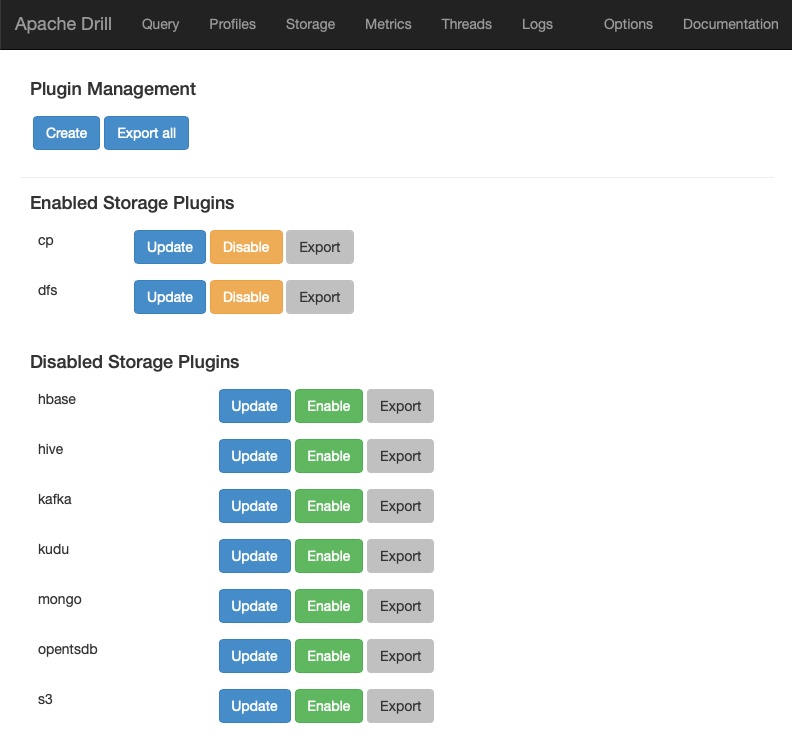
Drill Web App Plug-Ins
By clicking on the “Update” button for “dfs”, it is easy to modify the “workspace”, “location” and “defaultInputFormat” with the path to the file with your data as shown in Drill Web App Storage DFS Panel below. In our case, we changed the name of workspace to “root”, the location to “/Volumes/davidlucey/aDL/data/yelp_dataset/” and the defaultInputFormat to “json”. All the different data types are shown further down in “formats”, which is one of the big selling points. According to {sergeant}, it is possible to even combine disparate source types like: json, csv, parquet and rmdbs by modifying formats when configuring “dfs”, while pointing to almost any distributed file system. Once a path is configured in the plug-in, the data in that folder is all set to be queried from RStudio.
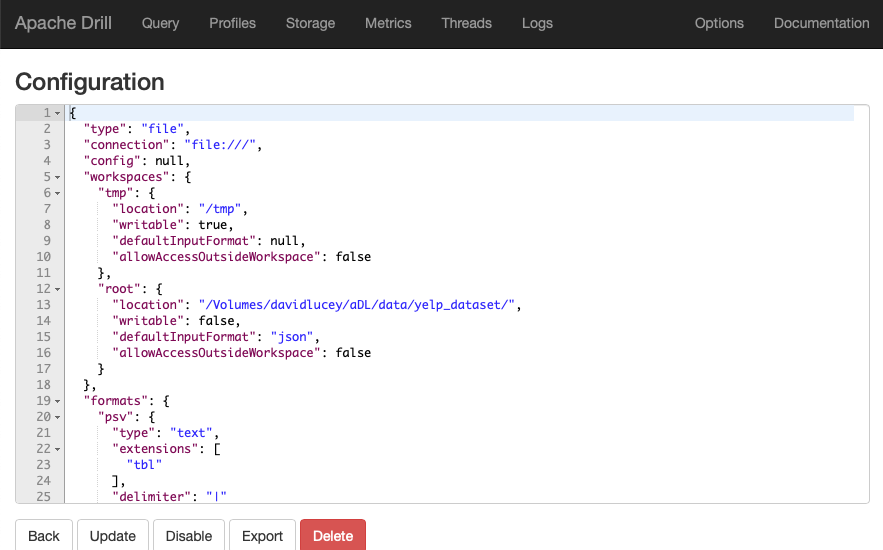
Drill Web App Storage DFS Panel
Connecting to Drill via dplyr
The first and most basic option to connect given by {sergeant} was via dplyr through the REST API, which was simple using src_drill() mapped to “localhost” port 8047. The resulting object lists the tables, including “dfs.root” workspace, which we configured in the dfs storage page above to point to the folder where we stored the Yelp JSON files. Note that there is no connection object involved with this option, and src_drill() doesn’t offer the option to specify much other than the host, port and user credentials.
db <- src_drill("localhost")
dbsrc: DrillConnection
tbls: cp.default, dfs.default, dfs.root, dfs.tmp, information_schema, sysHere we have loaded the key tables with the tbl() similar to Analyzing the Yelp Academic Dataset w/Drill & sergeant. Note the prefix “dfs.root”, followed by the name of the file from the specified Yelp Academic data set folder surrounded by back ticks. Our understanding is that {sergeant} uses jsonlite::fromJSON() to interact with the files while using the dplyr tbl() method to connect.
Click to see R code to set up check, yelp_biz, users & review
tbl()
tic.clearlog()
tic("Loading the four key datasets with: ")
check <- tbl(db, "dfs.root.`yelp_academic_dataset_checkin.json`")
yelp_biz <-
tbl(db, "dfs.root.`yelp_academic_dataset_business.json`")
users <- tbl(db, "dfs.root.`yelp_academic_dataset_user.json`")
review <- tbl(db, "dfs.root.`yelp_academic_dataset_review.json`")
toc(log = TRUE, quiet = TRUE)
yelp_biz.txt <- tic.log(format = TRUE)# Source: table<dfs.root.`yelp_academic_dataset_checkin.json`> [?? x 10]
# Database: DrillConnection
business_id date
<chr> <chr>
1 --1UhMGODdWsrMastO… 2016-04-26 19:49:16, 2016-08-30 18:36:57, 2016-10-15 02:…
2 --6MefnULPED_I942V… 2011-06-04 18:22:23, 2011-07-23 23:51:33, 2012-04-15 01:…
3 --7zmmkVg-IMGaXbuV… 2014-12-29 19:25:50, 2015-01-17 01:49:14, 2015-01-24 20:…
4 --8LPVSo5i0Oo61X01… 2016-07-08 16:43:30
5 --9QQLMTbFzLJ_oT-O… 2010-06-26 17:39:07, 2010-08-01 20:06:21, 2010-12-09 21:…
6 --9e1ONYQuAa-CB_Rr… 2010-02-08 05:56:47, 2010-02-15 04:47:42, 2010-02-22 03:…
7 --DaPTJW3-tB1vP-Pf… 2012-06-03 17:46:09, 2012-08-04 16:19:52, 2012-08-04 16:…
8 --DdmeR16TRb3LsjG0… 2012-11-02 21:26:42, 2012-11-02 22:30:43, 2012-11-02 22:…
9 --EF5N7P70J_UYBTPy… 2018-05-25 19:52:07, 2018-09-18 16:09:44, 2019-10-18 21:…
10 --EX4rRznJrltyn-34… 2010-02-26 17:05:40, 2012-12-29 20:05:04, 2012-12-30 22:…
# … with more rows# Source: table<dfs.root.`yelp_academic_dataset_business.json`> [?? x 22]
# Database: DrillConnection
business_id name address city state postal_code latitude longitude stars
<chr> <chr> <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl>
1 f9NumwFMBD… The … 10913 … Corn… NC 28031 35.5 -80.9 3.5
2 Yzvjg0Sayh… Carl… 8880 E… Scot… AZ 85258 33.6 -112. 5
3 XNoUzKckAT… Feli… 3554 R… Mont… QC H4C 1P4 45.5 -73.6 5
4 6OAZjbxqM5… Neva… 1015 S… Nort… NV 89030 36.2 -115. 2.5
5 51M2Kk903D… USE … 4827 E… Mesa AZ 85205 33.4 -112. 4.5
6 cKyLV5oWZJ… Oasi… 1720 W… Gilb… AZ 85233 33.4 -112. 4.5
7 oiAlXZPIFm… Gree… 6870 S… Las … NV 89118 36.1 -115. 3.5
8 ScYkbYNkDg… Junc… 6910 E… Mesa AZ 85209 33.4 -112. 5
9 pQeaRpvuho… The … 404 E … Cham… IL 61820 40.1 -88.2 4.5
10 EosRKXIGeS… Xtre… 700 Ki… Toro… ON M8Z 5G3 43.6 -79.5 3
# … with more rows, and 5 more variables: review_count <dbl>, is_open <dbl>,
# attributes <chr>, categories <chr>, hours <chr># Source: table<dfs.root.`yelp_academic_dataset_user.json`> [?? x 30]
# Database: DrillConnection
user_id name review_count yelping_since useful funny cool elite friends
<chr> <chr> <dbl> <chr> <dbl> <dbl> <dbl> <chr> <chr>
1 ntlvfP… Rafa… 553 2007-07-06 0… 628 225 227 "" oeMvJh…
2 FOBRPl… Mich… 564 2008-04-28 0… 790 316 400 "200… ly7EnE…
3 zZUnPe… Mart… 60 2008-08-28 2… 151 125 103 "201… Uwlk0t…
4 QaELAm… John 206 2008-09-20 0… 233 160 84 "200… iog3Ny…
5 xvu8G9… Anne 485 2008-08-09 0… 1265 400 512 "200… 3W3ZMS…
6 z5_82k… Steve 186 2007-02-27 0… 642 192 155 "200… E-fXXm…
7 ttumcu… Stua… 12 2010-05-12 1… 29 4 6 "" 1pKOc5…
8 f4_MRN… Jenn… 822 2011-01-17 0… 4127 2446 2878 "201… c-Dja5…
9 UYACF3… Just… 14 2007-07-24 2… 68 21 34 "" YwaKGm…
10 QG13XB… Clai… 218 2007-06-04 0… 587 372 426 "200… tnfVwT…
# … with more rows, and 13 more variables: fans <dbl>, average_stars <dbl>,
# compliment_hot <dbl>, compliment_more <dbl>, compliment_profile <dbl>,
# compliment_cute <dbl>, compliment_list <dbl>, compliment_note <dbl>,
# compliment_plain <dbl>, compliment_cool <dbl>, compliment_funny <dbl>,
# compliment_writer <dbl>, compliment_photos <dbl># Source: table<dfs.root.`yelp_academic_dataset_review.json`> [?? x 17]
# Database: DrillConnection
review_id user_id business_id stars useful funny cool text date
<chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <chr> <chr>
1 xQY8N_XvtG… OwjRMXRC… -MhfebM0QI… 2 5 0 0 "As someon… 2015-…
2 UmFMZ8PyXZ… nIJD_7ZX… lbrU8StCq3… 1 1 1 0 "I am actu… 2013-…
3 LG2ZaYiOgp… V34qejxN… HQl28KMwrE… 5 1 0 0 "I love De… 2015-…
4 i6g_oA9Yf9… ofKDkJKX… 5JxlZaqCnk… 1 0 0 0 "Dismal, l… 2011-…
5 6TdNDKywdb… UgMW8bLE… IS4cv902yk… 4 0 0 0 "Oh happy … 2017-…
6 L2O_INwlrR… 5vD2kmE2… nlxHRv1zXG… 5 2 0 0 "This is d… 2013-…
7 ZayJ1zWyWg… aq_ZxGHi… Pthe4qk5xh… 5 1 0 0 "Really go… 2015-…
8 lpFIJYpsvD… dsd-KNYK… FNCJpSn0tL… 5 0 0 0 "Awesome o… 2017-…
9 JA-xnyHytK… P6apihD4… e_BiI4ej1C… 5 0 0 0 "Most deli… 2015-…
10 z4BCgTkfNt… jOERvhmK… Ws8V970-mQ… 4 3 0 1 "I have be… 2009-…
# … with more rows[[1]]
[1] "Loading the four key datasets with: : 93.973 sec elapsed"It takes about two minutes to skim yelp_biz, which seems too long for ~210k rows, and definitely not worth it with the other, much larger files. Analyzing the Yelp Academic Dataset w/Drill & sergeant didn’t give the timing on its queries, but we assume it was much faster than this. The error message recommends that we CAST BIGINT columns to VARCHAR prior to working with them in dplyr, and suggests that we consider using R ODCBC with the MapR ODBC Driver because jsonlite::fromJSON() doesn’t support 64-bit integers. So, we are going to give ODBC a try in the next section and will set up a query to try to take this message into account to see if that makes a difference.
Click to see R code to skim Yelp Business JSON
tic.clearlog()
tic("Time to skim: ")
skim <- skimr::skim(yelp_biz)
toc(log = TRUE, quiet = TRUE)
yelp_biz_skim.txt <- tic.log(format = TRUE)── Data Summary ────────────────────────
Values
Name yelp_biz
Number of rows 209393
Number of columns 14
_______________________
Column type frequency:
character 9
numeric 5
________________________
Group variables None
── Variable type: character ────────────────────────────────────────────────────
skim_variable n_missing complete_rate min max empty n_unique whitespace
1 business_id 0 1 22 22 0 209393 0
2 name 0 1 0 64 1 157221 0
3 address 0 1 0 118 8679 164423 0
4 city 0 1 0 43 2 1243 0
5 state 0 1 2 3 0 37 0
6 postal_code 0 1 0 8 509 18605 0
7 attributes 0 1 2 1542 0 78140 0
8 categories 524 0.997 4 550 0 102494 0
9 hours 0 1 2 170 0 57641 0
── Variable type: numeric ──────────────────────────────────────────────────────
skim_variable n_missing complete_rate mean sd p0 p25 p50
1 latitude 0 1 38.6 4.94 21.5 33.6 36.1
2 longitude 0 1 -97.4 16.7 -158. -112. -112.
3 stars 0 1 3.54 1.02 1 3 3.5
4 review_count 0 1 36.9 123. 3 4 9
5 is_open 0 1 0.807 0.395 0 1 1
p75 p100 hist
1 43.6 51.3 ▁▂▇▆▂
2 -80.0 -72.8 ▁▁▇▁▇
3 4.5 5 ▁▃▃▇▆
4 27 10129 ▇▁▁▁▁
5 1 1 ▂▁▁▁▇[[1]]
[1] "Time to skim: : 262.239 sec elapsed"Setting up and Querying Drill with ODBC
First we had to download and install the MapR Drill ODBC Driver, which wasn’t difficult with the instructions here.
name attribute
6 ODBC Drivers MapR Drill ODBC Driver
7 MapR Drill ODBC Driver Description
8 MapR Drill ODBC Driver Driver
value
6 Installed
7 MapR Drill ODBC Driver
8 /Library/mapr/drill/lib/libdrillodbc_sbu.dylibHere was our connection using ODBC. Note that “ConnectionType” is specified as “Direct to Drillbit” Wiring Up Drill and R ODBC Style. If we were going with Zookeeper, ConnectionType should be “Zookeeper” and “ZKQuorum” “localhost:2181” instead. Since we have Zookeeper installed, we also tried this, but didn’t notice a big difference. When we run the ODBC connection below, the connection pain in RStudio shows four schemas (“c”, “d”, “i” and “s”), each having no tables.
Click to see R code to connect via ODBC
DBI::dbConnect(
odbc::odbc(),
driver = "MapR Drill ODBC Driver",
Host = "localhost",
Port = "31010",
ConnectionType = "Direct to Drillbit",
AuthenticationType = "No Authentication",
ZkClusterID = "drillbits1",
ZkQuorum = ""
) -> drill_con<OdbcConnection> Database: DRILL
Drill Version: 00.00.0000After setting up the connection, the {sergeant} manual returned a message with the current Drill version, but ours showed a Drill version of “00.00.0000”, so that might be part of to problem. We can see that connecting to the tables with ODBC took almost twice as long as with the dplyr connection, so it seems like we are doing something wrong. When we tried this with Zookeeper (not shown), it took 50 seconds, while 33 seconds with “Direct to Drillbit” (below).
tic.clearlog()
tic("Loading the four key datasets with ODBC: ")
check <-
tbl(drill_con,
sql("SELECT * FROM dfs.root.`yelp_academic_dataset_checkin.json`"))
yelp_biz <-
tbl(drill_con,
sql(
"SELECT * FROM dfs.root.`yelp_academic_dataset_business.json`"
))
users <-
tbl(drill_con,
sql("SELECT * FROM dfs.root.`yelp_academic_dataset_user.json`"))
review <-
tbl(drill_con,
sql("SELECT * FROM dfs.root.`yelp_academic_dataset_review.json`"))
toc()Loading the four key datasets with ODBC: : 133.307 sec elapsedtic.clearlog()The skim() for yelp_biz took about the same amount of time, but either way, it was still way too long to be a viable alternative. Again, “Direct to Drillbit” here took 116 seconds, while 81 seconds with Zookeeper, so we are clearly doing something wrong if all the things which are supposed to speed things up are actually slowing us down.
Click to see code to skim Yelp Business JSON with ODBC
tic("Skim yelp-biz with ODBC")
skim1 <- skimr::skim(yelp_biz)
toc(log = TRUE, quiet = TRUE)
yelp_odbc_skim.txt <- tic.log(format = TRUE)| Name | yelp_biz |
| Number of rows | 209393 |
| Number of columns | 14 |
| _______________________ | |
| Column type frequency: | |
| character | 11 |
| numeric | 3 |
| ________________________ | |
| Group variables | None |
Variable type: character
| skim_variable | n_missing | complete_rate | min | max | empty | n_unique | whitespace |
|---|---|---|---|---|---|---|---|
| business_id | 0 | 1 | 22 | 22 | 0 | 209393 | 0 |
| name | 0 | 1 | 0 | 64 | 1 | 157229 | 0 |
| address | 0 | 1 | 0 | 118 | 8679 | 164423 | 0 |
| city | 0 | 1 | 0 | 43 | 2 | 1251 | 0 |
| state | 0 | 1 | 2 | 3 | 0 | 37 | 0 |
| postal_code | 0 | 1 | 0 | 8 | 509 | 18605 | 0 |
| review_count | 0 | 1 | 18 | 21 | 0 | 1320 | 0 |
| is_open | 0 | 1 | 1 | 21 | 0 | 2 | 0 |
| attributes | 0 | 1 | 3 | 1713 | 0 | 78140 | 0 |
| categories | 524 | 1 | 4 | 550 | 0 | 102494 | 0 |
| hours | 0 | 1 | 3 | 206 | 0 | 57641 | 0 |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| latitude | 0 | 1 | 38.58 | 4.94 | 21.50 | 33.64 | 36.15 | 43.61 | 51.30 | ▁▂▇▆▂ |
| longitude | 0 | 1 | -97.39 | 16.72 | -158.03 | -112.27 | -111.74 | -79.97 | -72.81 | ▁▁▇▁▇ |
| stars | 0 | 1 | 3.54 | 1.02 | 1.00 | 3.00 | 3.50 | 4.50 | 5.00 | ▁▃▃▇▆ |
[[1]]
[1] "Skim yelp-biz with ODBC: 115.719 sec elapsed"Drill Web App
As we go along making queries, everything is collected in the Web App Profiles page, as shown in Drill Web App Query Profiles just below. Clicking on a query here takes us to the Query and Planning page, shown in further down in Drill Query and Planning Pane for Complicated SQL Query. There are other dashboards which we will show below.
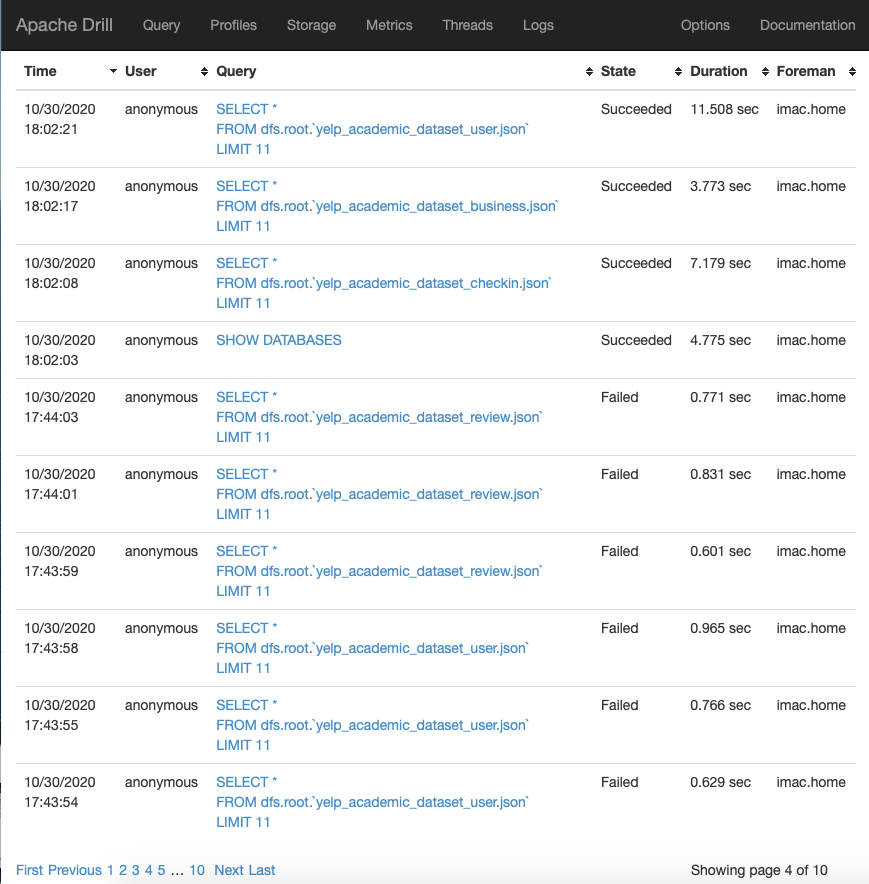
Drill Web App Query Profiles
Query Profiling with Drill
The other interesting thing in Drill was profiling. Here is a more complicated query we experimented with with a couple of joins and some aggregations for a query which wound up taking over an hour. See that we CAST the integer variables in this case as we were warned above, but that also didn’t seem to make a difference.
dq <-
odbc::dbGetQuery(drill_con,
"SELECT b1.name
,CAST(b1.stars AS INT) AS stars
,CAST(b1.review_count AS INT) AS review_count
,c.reviews
FROM (SELECT b.business_id
,COUNT(*) as reviews
FROM dfs.root.`yelp_academic_dataset_user.json` AS u,
dfs.root.`yelp_academic_dataset_review.json` AS r,
dfs.root.`yelp_academic_dataset_business.json` AS b
WHERE r.user_id = u.user_id
AND b.business_id = r.business_id
GROUP BY b.business_id, r.user_id
HAVING COUNT(*) > 10) AS c
INNER JOIN dfs.root.`yelp_academic_dataset_business.json` b1
ON c.business_id = b1.business_id"
)We are not running the query here in the blog post, but as mentioned, the timing can be seen in Drill Query and Planning Pane for Complicated SQL Query below the query at 1h11.
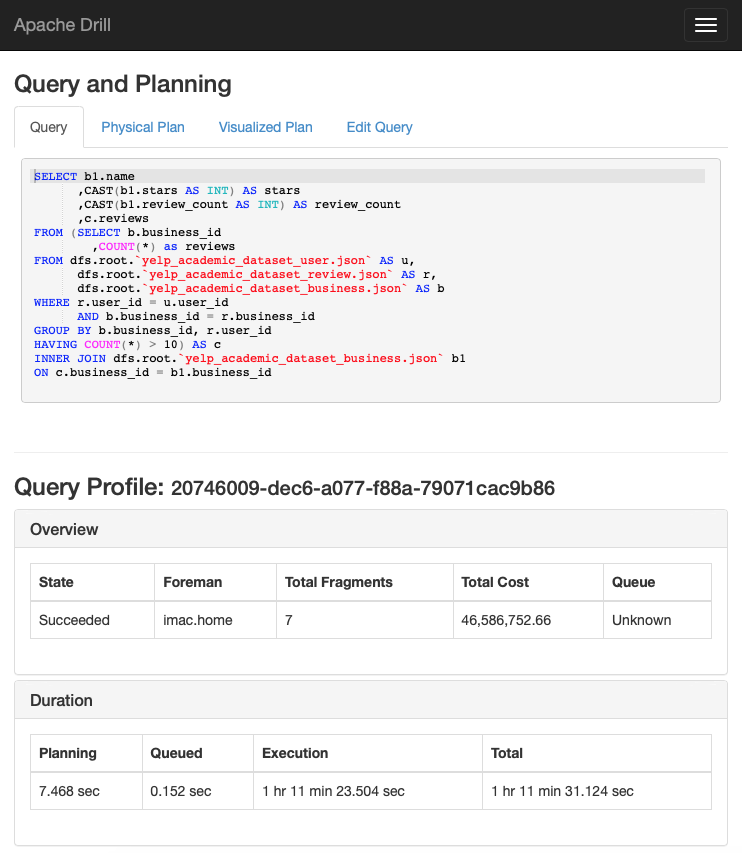
Drill Query and Planning Pane for Complicated SQL Query
It is amazing how much information about the query Drill gives us, shown in Drill Query and Planning Pane for Complicated SQL Query above Clicking on the “Edit Query” tab, and scrolling down to Operator Profiles (shown below), we can see that we some operators spilled to disc and that the scan operators spent more time waiting for data than processing it. We can also see that the Hash Aggregate in Fragment 1 took 13% of the query time. Further down but not shown, the Hash Joins took almost 70% of the query time, so the Hash Joins and Hash Aggregate together took 70% of the query time. Even without those bottlenecks, we probably still wouldn’t have been satisfied with the amount of time this took. Having this information, it seems like it would be possible to optimize, but we didn’t know how to do it. We have been recently learning SQL and realize that there is still a lot to learn.
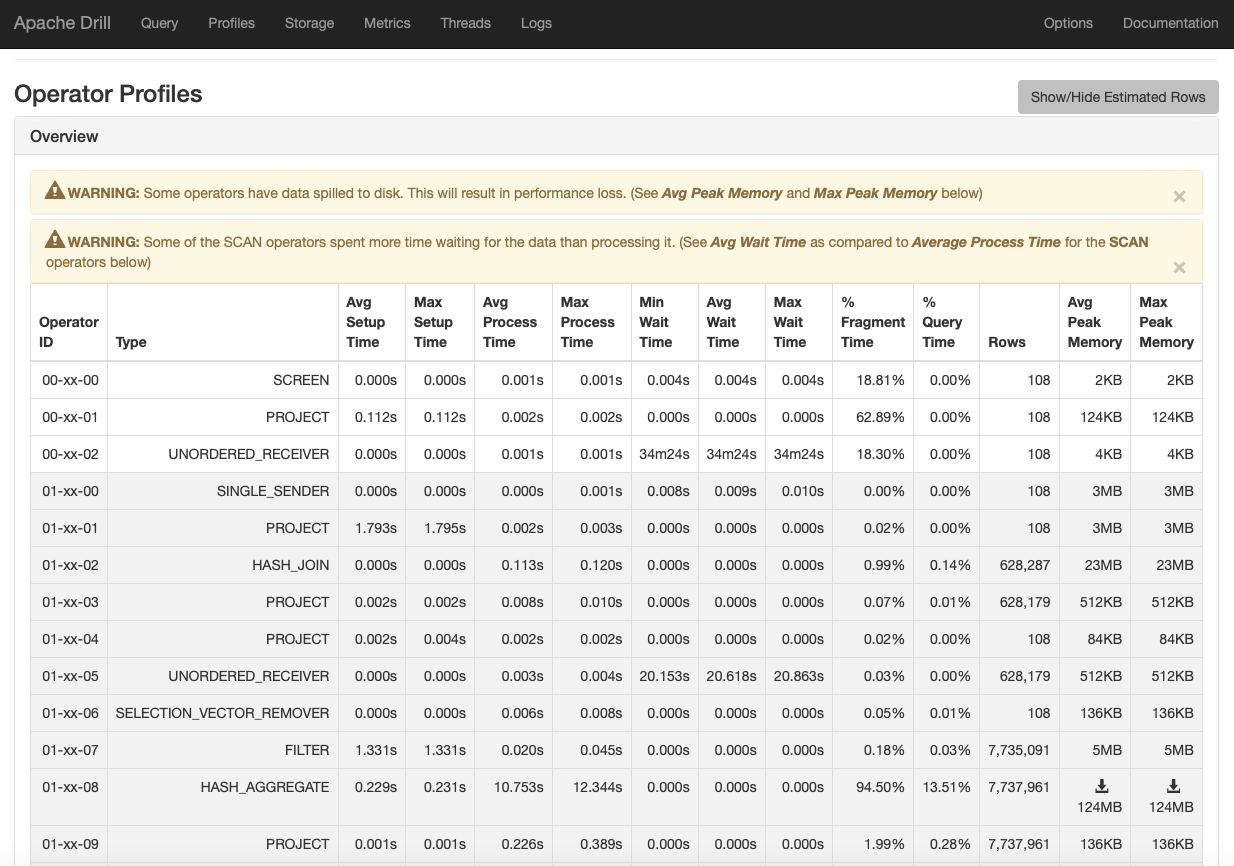
Drill Operator Profiles for Complicated SQL Query
Lastly, Drill has a nice dashboard which allowed us to for example instruct the hash joins and hash aggregations to ignore memory limits as shown in Drill Web App - Options Panel below. There were a lot of parameter settings available, but we were not sure how to adjust these to solve our specific problems, but would welcome any good advice or pointers.
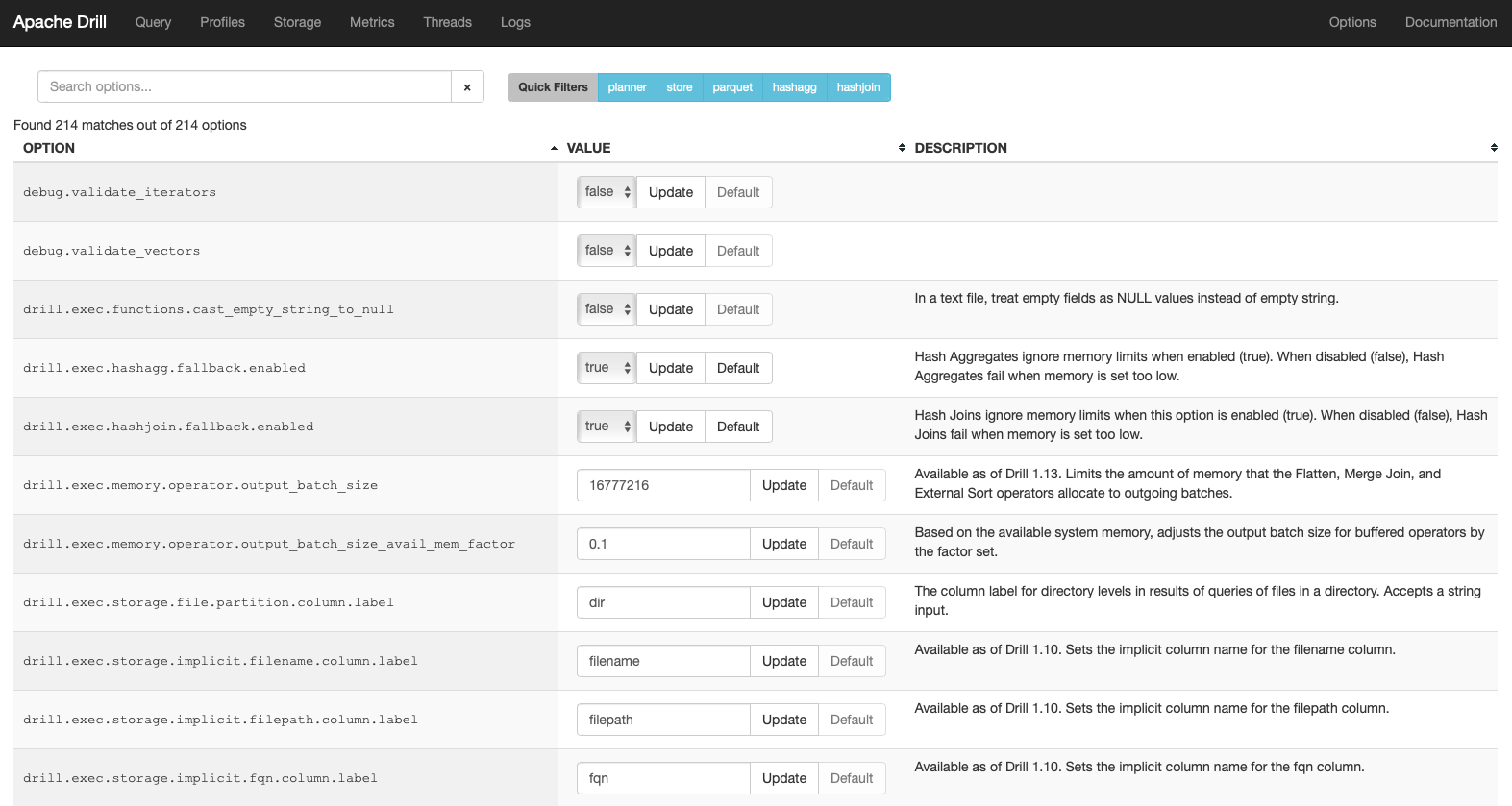
Drill Web App - Options Panel
Clean up
Shutting down when done is also easy as shown here.
/usr/local/apache-drill-1.17.0/bin/drillbit.sh stopReturning to JDK 14.0
jenv global 14.0.2Conclusion
We don’t know the status of Drill given “orphan” status, but there wasn’t much current discussion that we could find with a quick search. If these problems are fixable, we would be very grateful for feedback and promise to update this post for the benefit of others. We have read that the arrow package is a lot faster than this on similar sized data, but don’t know if it is as flexible. If there is a clearly better open source way to accomplish these objectives, such as arrow, any guidance would be much appreciated.